Designing 500K/Minute Notification Platform: From Whiteboard to Production
How modern enterprises deliver half a million notifications per minute reliably across Email, SMS, Push, WebSocket, Mobile Push, and In-App channels.
Introduction
Every large digital platform eventually faces the same challenge:
“How do we notify millions of users in real-time without overwhelming our systems, providers, or customers?”
Architectural Blueprint: Designing a Notification Platform for 500k Ops/Min
In the modern digital ecosystem, communication is the lifeblood of user engagement and operational integrity. Whether you are architecting a fast-paced e-commerce platform, a secure banking application, a global supply chain management system, a multi-tenant SaaS product, a compliant healthcare platform, or a massive IoT ecosystem—notifications are not just a feature. They are a critical piece of core infrastructure.
Yet, despite its importance, notification delivery is frequently treated as an afterthought. This is a costly mistake.
The Cost of Failure
When a notification system is poorly designed, the blast radius impacts the entire business.
| Please refer below points. these poins describes how it manifests | ||
|---|---|---|
| * Customer Frustration: | – Delayed OTPs, missed critical alerts, or spammy, uncoordinated messaging. | |
| * Lost Revenue: | – Failed transactional emails that stall checkout pipelines and lower conversion rates. | |
| * Compliance Violations: | – Failing to deliver time-sensitive legal disclosures or breaching strict healthcare and financial privacy laws. | |
| * Escalating Cloud Costs: | – Unoptimized retry logic, runaway queues, and inefficient compute utilization that bloat your monthly bill. | |
| * Production Incidents: | – Downstream provider outages choking your core application threads, leading to full-scale system degradation. |
To prevent these pitfalls, you need a system engineered for high availability, fault tolerance, and massive throughput.
What This Guide Covers
This article provides a comprehensive, end-to-end blueprint for designing, building, and operating an enterprise-grade notification platform capable of handling 500,000 notifications per minute.
We will walk through the complete lifecycle of this system—moving from initial business requirements and technical constraints, through architectural design patterns, to the battle-tested strategies required for global-scale production operations.
Ready to scale? Let’s dive into the core architecture.
Lifecycle Blueprint: Engineering a 500k Ops/Min Enterprise Notification Platform
Phase 1: Business Vision & Problem Definition
Every successful platform starts by addressing a tangible business problem. Imagine a global SaaS enterprise serving 10 million users and 5,000 enterprise customers across 50 countries.
To maintain operational integrity and engagement, the business must reliably deliver notifications across multiple verticals:
- Transactional: Order updates, workflow approvals, and system alerts.
- Security & Compliance: Security events, time-sensitive compliance notifications.
- Operational: IoT device failures, system monitoring alerts.
- Growth: Targeted marketing campaigns.
Target Baseline Scale
| Metric / Parameter | Target Enterprise Value |
| Active User Base | 10 Million Users |
| Peak Throughput | 500,000 notifications / minute |
| Supported Channels | Email, SMS, Mobile Push, In-App |
| System Availability | 99.99% (Four Nines) |
| Geographic Footprint | Multi-region active-active deployment |
| Delivery SLA | $< 5$ seconds end-to-end delivery |
Phase 2: Requirements Engineering
Before drawing architecture diagrams, architectural teams must clearly delineate between what the system does (functional) and how it performs (non-functional).
Functional Requirements
- Omnichannel Delivery: Native support for Email, SMS, Push, and In-App notifications.
- User Preferences: Granular opt-in/opt-out controls per channel and notification type.
- Template Registry: Dynamic rendering engine with localization and version control.
- Scheduling Engine: Support for immediate, delayed, or recurring dispatches.
- Resiliency Mechanisms: Automatic retries, backoff strategies, and fallback channels.
- Multi-Tenant Isolation: Complete data and performance segregation between enterprise clients.
- Audit Trails: Comprehensive notification history and delivery state tracking.
Non-Functional Requirements
- High Availability & Fault Tolerance: Elimination of single points of failure.
- Strict Security & Compliance: Zero cross-tenant leakage, encrypted data layers.
- Observability: End-to-end distributed tracing and real-time lag monitoring.
- Scalability & Cost Efficiency: Horizontal scaling with optimized cloud resource compute spend.
Phase 3: Capacity Planning
A high-volume notification platform cannot be designed on intuition; it must be engineered around calculated metrics.
1. Traffic Estimation
-
Peak Volume: 500,000 notifications/minute
-
Peak Per-Second Throughput:
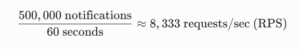
-
Daily Aggregate Traffic:
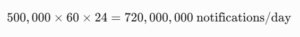
2. Storage Estimation
Assuming an average payload size of 1 KB per notification (metadata, references, and content):

Architectural Note: Given these numbers, multi-tiered storage strategies and aggressive retention policies are mandatory rather than optional.
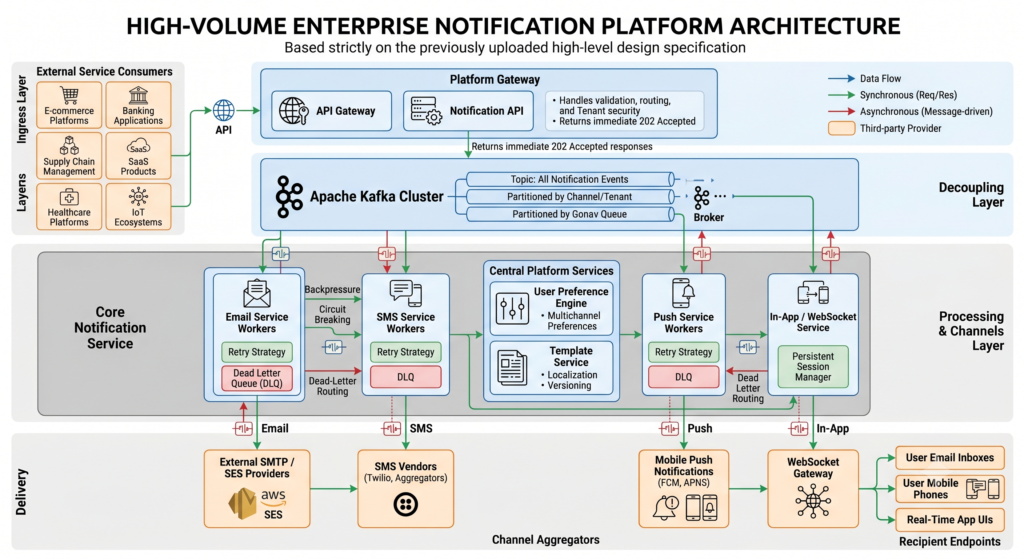
Phase 4: High-Level Architecture
At this stage, the foundational design principle is established: Never process or deliver notifications synchronously. Synchronous processing binds your API availability to downstream third-party vendors.
[ Client Applications ]
│
▼
[ API Gateway ]
│
▼
[ Notification API ]
│
▼
[ Kafka Cluster ]
│
┌──────┼────────┐
▼ ▼ ▼
[Email] [SMS] [Push] <-- Microservice Worker Pools
│ │ │
▼ ▼ ▼
[ SES ] [Twilio] [FCM] <-- Downstream Third-Party Providers
The Async Pipeline Sequence
- Accept Request: Validate the inbound payload at the API layer.
- Persist Request: Immediately hand off the event to a highly durable message broker.
- Acknowledge Client: Return a
202 Acceptedstatus with a tracking ID under $< 50\text{ms}$. - Process Asynchronously: Decoupled worker pools pull from the broker and manage delivery.
Phase 5: Event-Driven Core (Apache Kafka)
As traffic scales to 8.3k+ RPS, direct service-to-service communication risks cascading failures. The platform introduces Apache Kafka as its central nervous system.
Key Architectural Benefits
- Horizontal Scalability: Partitioning channels allows multiple consumers to process events in parallel.
- Backpressure Buffering: During provider slowdowns, Kafka safely queues messages without degrading client APIs.
- Consumer Independence: The Email worker group and the SMS worker group process the same or separate event streams at their own pace.
Normalized Event Payload Schema
{
"tenantId": "acme_corp_789",
"userId": "usr_10x82649",
"channel": "EMAIL",
"template": "ORDER_CONFIRMED",
"context": {
"firstName": "Alex",
"orderId": "ord_99482A"
}
}
Phase 6: Channel Processing Layer
To avoid a monolithic failure where a bottlenecked SMS provider halts email deliveries, the system splits processing into isolated, channel-specific microservices.
Notification Platform Engine
├── Email Service (Scales on SMTP/SES throughput metrics)
├── SMS Service (Scales on Twilio/regional aggregator limits)
├── Push Service (Optimized for HTTP/2 persistent connections to FCM/APNS)
├── In-App Service (Optimized for rapid write operations to operational databases)
└── WebSocket Service (Manages high-concurrency stateful user connections)
By decoupling these layers, one overloaded or malfunctioning channel has zero blast radius on the performance of the others.
Phase 7: Reliability Engineering
Downstream provider outages, network partitions, and consumer crashes are inevitable at scale. The platform employs three primary resilience patterns:
1. Exponential Backoff Retry Strategy
Instead of hammering an unavailable downstream provider, workers back off exponentially:
- Attempt 1: Immediate retry on transient failure.
- Attempt 2: 30-second delay.
- Attempt 3: 5-minute delay.
- Attempt 4: 30-minute delay.
2. Dead Letter Queues (DLQ)
Messages failing all retry attempts are routed to a specialized notification-dlq topic. This prevents poison-pill messages from blocking consumer offsets, guarantees zero data loss, and allows engineers to safely replay messages after fixing underlying bugs.
3. Circuit Breakers
If a downstream provider (e.g., an SMS vendor) exhibits a failure rate $> 50\%$, the circuit breaker trips Open.
[ Normal Flow: Circuit Closed ] ──> Requests stream to Provider
│
▼ (Failure threshold crossed)
[ Outage Flow: Circuit Open ] ──> Fail fast or divert to Fallback Aggregator immediately
This prevents workers from wasting execution threads on requests destined to fail.
Phase 8: User Preference Engine
To maintain user trust, reduce spam, and minimize unnecessary channel costs, notifications must pass through a strict preference filter before execution.
Multi-Dimensional Preference Matrix
| Event Category | Email Channel | SMS Channel | Push Channel |
|---|---|---|---|
| Order Update | ✅ Yes | ✅ Yes | ✅ Yes |
| Marketing Promotional | ❌ No | ❌ No | ✅ Yes |
| Security Alert | ✅ Yes | ✅ Yes | ✅ Yes |
The Preference Engine evaluates user selections in real time against the incoming payload. If an event is opted out, the pipeline drops it immediately, preventing downstream processing fees.
Phase 9: Template Management Platform
Hardcoding message copy inside service code limits agility. The platform abstracts messaging copy into a centralized Notification Template Service.
Architecture Implementation
Templates use standard interpolation engines (e.g., Handlebars or Mustache) stored in highly cached distributed memory (like Redis):
<p>Hello {{firstName}},</p>
<p>Your order <strong>{{orderId}}</strong> has successfully shipped!</p>
Strategic Benefits
- Localization: Automatic mapping to the user’s preferred language locale.
- Branding Integrity: Universal header and footer changes applied globally.
- Versioning: Rollback capability on copy or layout errors without service redeployments.
Phase 10: Real-Time Notification Delivery (WebSockets)
Traditional HTTP polling strains database infrastructures and introduces unwanted latency. For instant interactive elements—such as live tracking, trading alerts, and chat—the platform utilizes a persistent connection model.
[ User Browser / App ] 🚀 Persistent Duplex Connection
▲
▼
[ WebSocket Gateway ]
▲
▼
[ Notification Stream ]
When a worker processes an in-app notification, it checks if the user has an active connection instance pinned to a WebSocket gateway node. If present, the message bypasses external channels and pushes directly to the active client UI in milliseconds.
Phase 11: Multi-Tenant Architecture
For global B2B SaaS configurations, strict isolation protocols protect tenant boundaries and prevent the “noisy neighbor” effect.
Isolation Frameworks
- Logical Segregation: Every message envelope carries a mandatory
tenantIdchecked against execution parameters. - Rate-Limit Quotas: Multi-tenant token-bucket algorithms prevent Tenant A from consuming all available Kafka worker threads during a massive marketing blast, preserving bandwidth for Tenant B.
- Custom Security Configurations: Allows distinct tenants to supply their own vendor credentials (e.g., their own Twilio or SES accounts).
Phase 12: Security & Compliance Architecture
Security is woven directly into the infrastructure layout, covering four primary fields:
- Authentication & Authorization: Secure internal inter-service communication via OAuth2 and JWT validation. Role-Based Access Control (RBAC) governs template and configuration access.
- Data Protection: Implement Transport Layer Security (TLS 1.3) for all data in transit and AES-256 encryption for data at rest across databases and log aggregators.
- Anonymization & Masking: Stripping or masking Personally Identifiable Information (PII) like phone numbers or medical IDs before logging execution details.
- Regulatory Compliance: Adherence to localized guidelines including GDPR (right to be forgotten deletion mechanics), HIPAA (healthcare data constraints), and SOC2 Type II audit trails.
Phase 13: Observability Platform
Operating at 500,000 notifications per minute makes debugging individual failures impossible without uniform telemetry. Observability is treated as a critical production pillar.
Telemetry Implementation
[ Metrics Engine ] ──> Monitors Queue Depths, Channel Success Rates, and Kafka Consumer Lag
[ Logging Matrix ] ──> Captures Request Envelopes, Tenant Context, and Provider Response Strings
[ Tracing Fabric ] ──> Tracks Trace IDs across API -> Kafka -> Worker -> Provider Endpoints
With an integrated tracing fabric, engineers can profile exactly why a specific notification took more than the allotted 5-second SLA, pinpointing whether the latency occurred within internal queues or third-party gateways.
Phase 14: Disaster Recovery (DR)
To guarantee a 99.99% availability target, the system must survive full cloud availability zone and regional infrastructure blackouts.
Multi-Region Infrastructure Mapping
- Multi-AZ Availability: Compute workers and database replicas span at least three availability zones within a region, handling instantaneous failovers.
- Active-Active Cross-Region Replication: Key operational databases and Kafka topics replicate asynchronously across geographical zones (e.g., US-East to Europe).
- Definitive Recovery Objectives:
- Recovery Point Objective (RPO): $< 5 \text{ Minutes}$ of permissible data sync lag.
- Recovery Time Objective (RTO): $< 30 \text{ Minutes}$ to fully redirect global production traffic during a massive regional disaster.
Phase 15: Cost Optimization
At scale, inefficient notification patterns drastically inflate monthly cloud infrastructure statements.
Key Financial Optimization Targets
- Intelligent Batching: Grouping low-priority notifications (e.g., digest summaries) into single deliveries instead of launching thousands of separate requests.
- Tiered Storage Architecture: Moving operational notification logs over 14 days old out of expensive high-IOPS databases into lower-cost object storage (e.g., AWS S3).
- Channel Routing Optimization: Utilizing Push notifications as a primary fallback channel before triggering expensive network options like SMS.
- Dynamic Auto-Scaling: Auto-scaling worker pools up or down based on current Kafka partition lag metrics to avoid paying for idle compute power.
Phase 16: Platform Engineering & Self-Service
Rather than forcing individual feature squads to build independent delivery mechanisms, a dedicated Notification Platform Team centralizes delivery logic.
[ Core Notification Platform Team ]
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
[ Shared APIs ] [ Client SDKs ] [ Governance Tools ]
│ │ │
└─────────────────┼─────────────────┘
▼
[ Multi-Vertical Product Teams ]
Internal squads use standardized software development kits (SDKs) and user interface dashboards to register templates, track their specific vertical’s metrics, and manage customer interactions without needing to configure underlying cloud message brokers.
Phase 17: Governance & Architecture Reviews
Enterprise production readiness requires structured architectural reviews across key fundamental pillars before pushing modifications live:
- Capacity & Performance: Can the layout comfortably maintain 8.3k RPS under peak loads?
- Resilience & DR: Are the circuit breakers, retry tolerances, and RTO parameters validated?
- Security & Compliance: Is data anonymization verified and does it meet tenant isolation rules?
- Data Architecture: Are storage retention policies automatically purging historical records?
- Operability & Cost: Are alerts properly calibrated and is the channel selection strategy financially sound?
Phase 18: AI-Powered Platform Evolution
Modern notification architectures leverage machine learning models directly inside the streaming pipeline to maximize engagement and minimize delivery friction:
- Smart Channel Routing: Predicts whether a user is more likely to open an email or interact with a mobile push notification based on historical interaction habits.
- Dynamic Prioritization: Dynamically re-orders worker queues, placing high-value transactional alerts (like OTPs) ahead of routine informational updates.
- Send-Time Optimization (STO): Schedules marketing or non-urgent updates for the exact hour a user typically engages with their device.
- Anomaly Detection Engines: Instantly identifies automated spam injection vectors, unexpected third-party drop-offs, or configuration errors before they impact downstream customers.
Final Production Architecture Overview
The unified enterprise notification topology acts as a reliable, highly available, and fully observable delivery engine designed for continuous enterprise scale:
[ External Applications / Microservices ]
│
▼
[ API Gateway ]
│
▼
[ Notification API ]
│
▼
[ Kafka Event Cluster ]
│
┌──────────────┼──────────────┬──────────────┐
▼ ▼ ▼ ▼
[ Email ] [ SMS ] [ Push ] [ In-App ] <-- Isolated Worker Pools
│ │ │ │
▼ ▼ ▼ ▼
[ SES ] [ Twilio ] [ FCM ] [ WebSockets ] <-- End Delivery Targets